前回の記事では、MastraとActiveReportsJSで実現する日報AIエージェントの第1弾として、Next.jsプロジェクトの作成とMastraの統合、Mastraのサンプルコードを用いたエージェント構築の基本についてご紹介しました。
今回の記事では、日報の登録に必要となるデータベースの作成、日報データの登録処理、帳票レイアウトファイルの取得処理などをエージェントに実装する方法についてご紹介します。
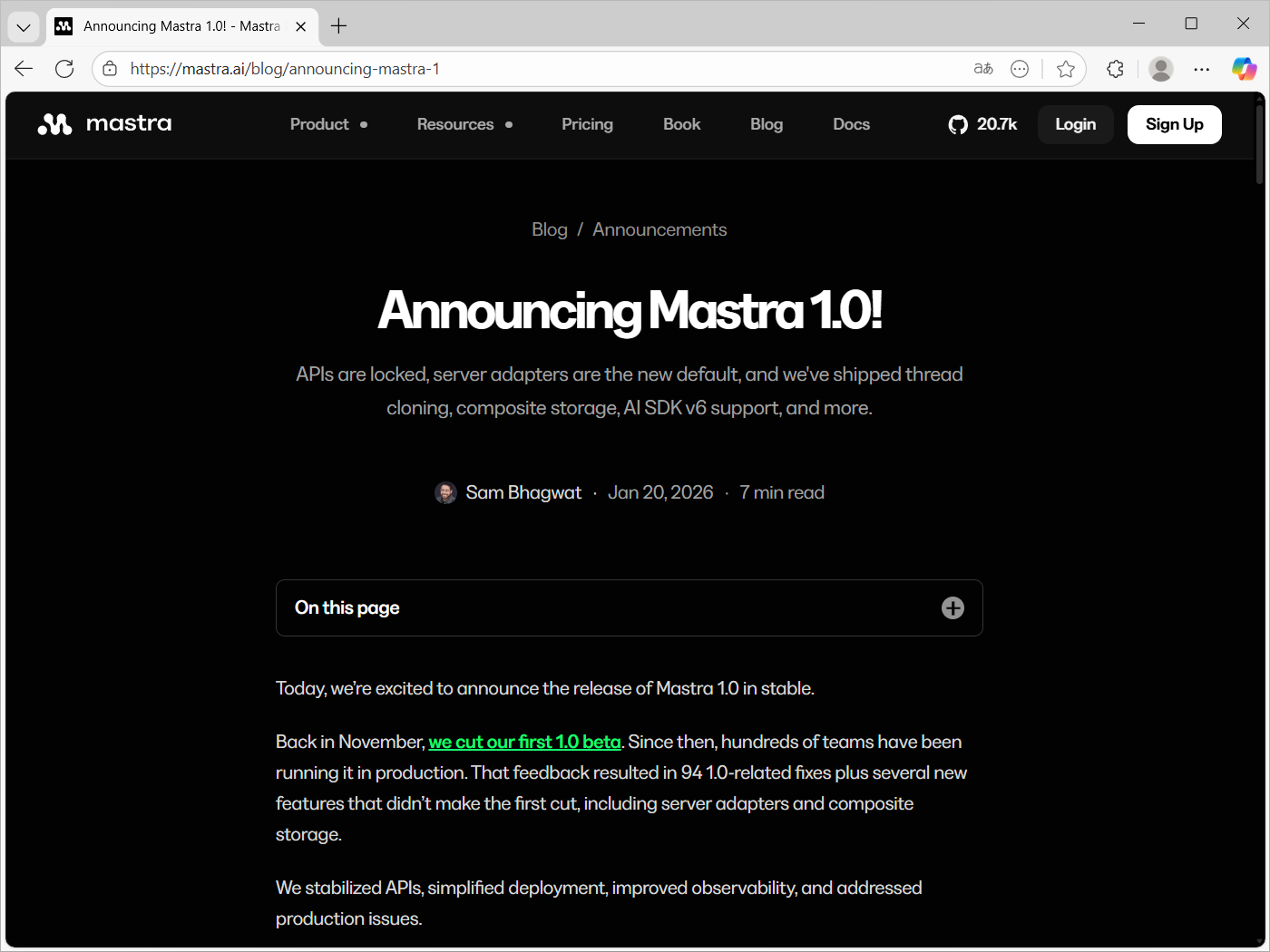
あわせて、本連載で利用しているエージェントフレームワーク「Mastra」が先日「Mastra 1.0」として正式リリースされました。本記事では、旧バージョンからの移行ポイントについてもご紹介します。
Mastra 1.0!
Mastra 1.0 がリリース。これまでのMastraは0.x系として提供され、エージェントやワークフローのPoCや検証用途を中心に多くのユーザーに利用されてきましたが、今回リリースされた1.0ではAPIの安定化に加え、既存のサーバーに組み込めるServer Adapters、ドメインごとに最適化できるComposite Storage、最新のAI SDK v6サポートなど、本番利用を意識した強化が行われています。
前回作成したプロジェクトはMastra0.x系をベースとしているため、本記事ではMastra1.0への移行を行ったうえで、各実装を行っていきます。
すべてのMastraパッケージを最新にする
まず最初に以下のコマンドで、プロジェクトのすべてのMastraパッケージを最新にします。
npm install mastra@latest @mastra/core@latest @mastra/loggers@latest @mastra/memory@latest @mastra/libsql@latestNode.jsのバージョンを更新する
Mastra 1.0を利用するにはNode.js 22.13.0以降が必要です。あらかじめインストールされているNode.jsのバージョンを確認し、必要に応じてアップデートを行ってください。
codemodの実行(0.xから1.0への移行支援ツール)
続いて、移行支援ツールとして用意されている「codemod」というCLIツールを、プロジェクトの直下で実行します。以下のコマンドを実行してください。
npx @mastra/codemod@latest v1codemodを実行すると、次のようにFIXME(mastra):と書かれているコメント箇所を検索して、手動で修正するように指示されます。
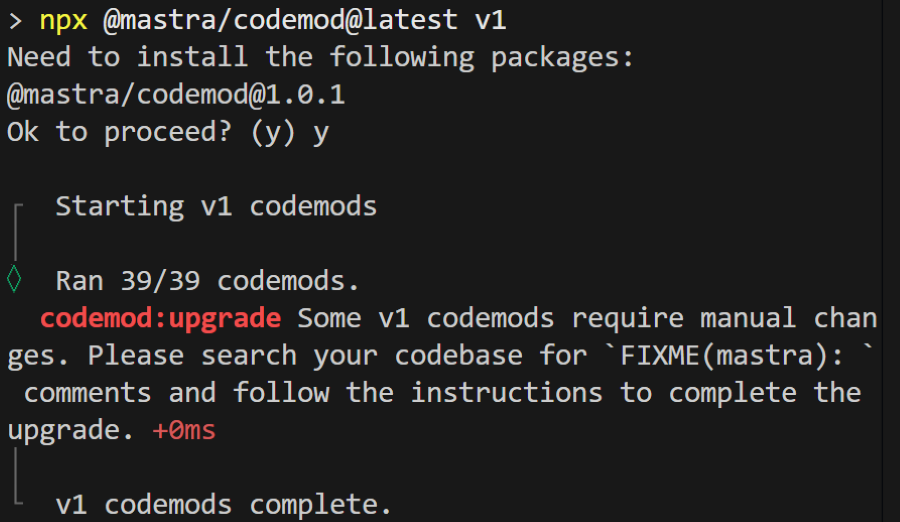
検索すると、該当箇所が3箇所ありますので、コメントの指示に従い修正します。
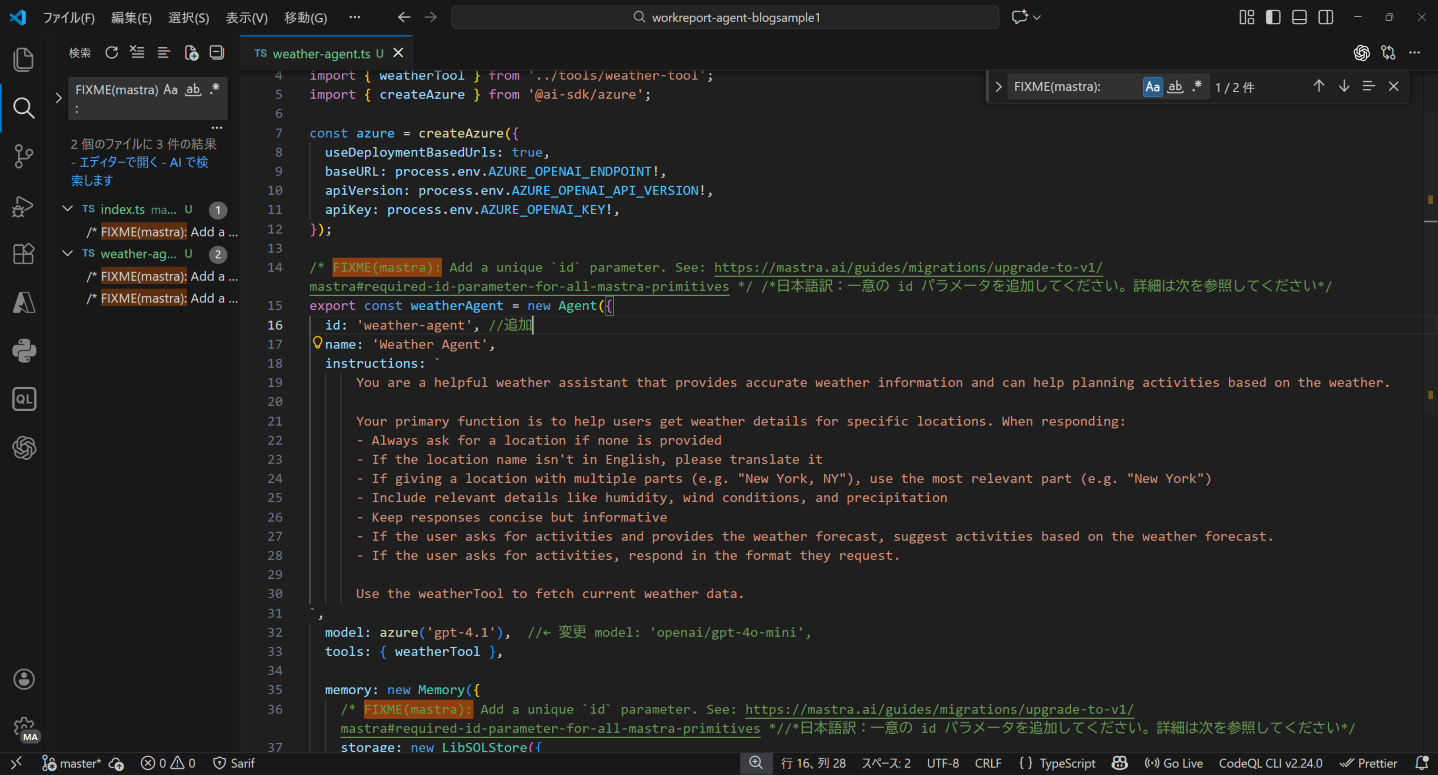
codemodのコメントに従って修正しても、一部のケースではエラーが発生したり、期待通りに動作しない場合があります。
Mastra 1.0では設定構成や責務の整理が行われており、codemodでは対応できない変更点があります。
主なポイントは以下のとおりです。
LLM設定の構成変更
Azure OpenAIを利用している場合、@ai-sdk/azureをエージェント側で直接使用するのではなく、AzureOpenAIGatewayを用いてindex.tsでGatewayとして定義します。
Observability設定の構成変更(実行ログやトレースなどの可観測性に関する設定)
Observabilityの設定は引き続きindex.tsに記述しますが、v1では@mastra/observabilityを利用する形に変更されています。そのため、Observabilityを利用する場合は、次のコマンドでパッケージをインストールしてください。
npm install @mastra/observability@latestcodemodで修正できない箇所については、以下の公式移行ガイドに記載されている変更点を確認したうえで、必要な移行作業を行ってください。
コードの修正
今回修正が必要となる、コードは以下の通りとなります。強調表示した箇所が変更箇所です。
import { Mastra } from '@mastra/core/mastra';
import { AzureOpenAIGateway } from '@mastra/core/llm';
import { PinoLogger } from '@mastra/loggers';
import { LibSQLStore } from '@mastra/libsql';
import { Observability, DefaultExporter, CloudExporter, SensitiveDataFilter } from '@mastra/observability';
import { weatherWorkflow } from './workflows/weather-workflow';
import { weatherAgent } from './agents/weather-agent';
export const mastra = new Mastra({
gateways: {
azureOpenAI: new AzureOpenAIGateway({
resourceName: process.env.AZURE_OPENAI_RESOURCE_NAME!, //環境変数の追加が必要です。
apiVersion: process.env.AZURE_OPENAI_API_VERSION!,
apiKey: process.env.AZURE_OPENAI_KEY!,
deployments: ["gpt-4.1"],
}),
},
workflows: { weatherWorkflow },
agents: { weatherAgent },
/* FIXME(mastra): Add a unique `id` parameter. See: https://mastra.ai/guides/migrations/upgrade-to-v1/mastra#required-id-parameter-for-all-mastra-primitives */
storage: new LibSQLStore({
// stores observability, scores, ... into memory storage, if it needs to persist, change to file:../mastra.db
id: 'mastra-storage',
url: ":memory:",
}),
logger: new PinoLogger({
name: 'Mastra',
level: 'info',
}),
observability: new Observability({
configs: {
default: {
serviceName: 'mastra',
exporters: [
new DefaultExporter(), // Persists traces to storage for Mastra Studio
new CloudExporter(), // Sends traces to Mastra Cloud (if MASTRA_CLOUD_ACCESS_TOKEN is set)
],
spanOutputProcessors: [
new SensitiveDataFilter(), // Redacts sensitive data like passwords, tokens, keys
],
},
},
}),
// telemetry: {
// // Telemetry is deprecated and will be removed in the Nov 4th release
// enabled: false,
// },
// observability: {
// // Enables DefaultExporter and CloudExporter for AI tracing
// default: { enabled: true },
// },
});
import { Agent } from '@mastra/core/agent';
import { Memory } from '@mastra/memory';
import { LibSQLStore } from '@mastra/libsql';
import { weatherTool } from '../tools/weather-tool';
//import { createAzure } from '@ai-sdk/azure';
// const azure = createAzure({
// useDeploymentBasedUrls: true,
// baseURL: process.env.AZURE_OPENAI_ENDPOINT!,
// apiVersion: process.env.AZURE_OPENAI_API_VERSION!,
// apiKey: process.env.AZURE_OPENAI_KEY!,
// });
/* FIXME(mastra): Add a unique `id` parameter. See: https://mastra.ai/guides/migrations/upgrade-to-v1/mastra#required-id-parameter-for-all-mastra-primitives */ /*日本語訳:一意の id パラメータを追加してください。詳細は次を参照してください*/
export const weatherAgent = new Agent({
id: 'weather-agent', //追加
name: 'Weather Agent',
instructions: `
You are a helpful weather assistant that provides accurate weather information and can help planning activities based on the weather.
Your primary function is to help users get weather details for specific locations. When responding:
- Always ask for a location if none is provided
- If the location name isn't in English, please translate it
- If giving a location with multiple parts (e.g. "New York, NY"), use the most relevant part (e.g. "New York")
- Include relevant details like humidity, wind conditions, and precipitation
- Keep responses concise but informative
- If the user asks for activities and provides the weather forecast, suggest activities based on the weather forecast.
- If the user asks for activities, respond in the format they request.
Use the weatherTool to fetch current weather data.
`,
//model: azure('gpt-4.1'), //← 変更 model: 'openai/gpt-4o-mini',
model: "azure-openai/gpt-4.1",
tools: { weatherTool },
memory: new Memory({
/* FIXME(mastra): Add a unique `id` parameter. See: https://mastra.ai/guides/migrations/upgrade-to-v1/mastra#required-id-parameter-for-all-mastra-primitives *//*日本語訳:一意の id パラメータを追加してください。詳細は次を参照してください*/
storage: new LibSQLStore({
id: 'weather-agent-memory', //追加
url: 'file:../mastra.db', // path is relative to the .mastra/output directory
}),
}),
});
import { createTool } from '@mastra/core/tools';
import { z } from 'zod';
interface GeocodingResponse {
results: {
latitude: number;
longitude: number;
name: string;
}[];
}
interface WeatherResponse {
current: {
time: string;
temperature_2m: number;
apparent_temperature: number;
relative_humidity_2m: number;
wind_speed_10m: number;
wind_gusts_10m: number;
weather_code: number;
};
}
export const weatherTool = createTool({
id: 'get-weather',
description: 'Get current weather for a location',
inputSchema: z.object({
location: z.string().describe('City name'),
}),
outputSchema: z.object({
temperature: z.number(),
feelsLike: z.number(),
humidity: z.number(),
windSpeed: z.number(),
windGust: z.number(),
conditions: z.string(),
location: z.string(),
}),
execute: async ({ location }) => {
return await getWeather(location);
},
});
const getWeather = async (location: string) => {
const geocodingUrl = `https://geocoding-api.open-meteo.com/v1/search?name=${encodeURIComponent(location)}&count=1`;
const geocodingResponse = await fetch(geocodingUrl);
const geocodingData = (await geocodingResponse.json()) as GeocodingResponse;
if (!geocodingData.results?.[0]) {
throw new Error(`Location '${location}' not found`);
}
const { latitude, longitude, name } = geocodingData.results[0];
const weatherUrl = `https://api.open-meteo.com/v1/forecast?latitude=${latitude}&longitude=${longitude}¤t=temperature_2m,apparent_temperature,relative_humidity_2m,wind_speed_10m,wind_gusts_10m,weather_code`;
const response = await fetch(weatherUrl);
const data = (await response.json()) as WeatherResponse;
return {
temperature: data.current.temperature_2m,
feelsLike: data.current.apparent_temperature,
humidity: data.current.relative_humidity_2m,
windSpeed: data.current.wind_speed_10m,
windGust: data.current.wind_gusts_10m,
conditions: getWeatherCondition(data.current.weather_code),
location: name,
};
};
function getWeatherCondition(code: number): string {
const conditions: Record<number, string> = {
0: 'Clear sky',
1: 'Mainly clear',
2: 'Partly cloudy',
3: 'Overcast',
45: 'Foggy',
48: 'Depositing rime fog',
51: 'Light drizzle',
53: 'Moderate drizzle',
55: 'Dense drizzle',
56: 'Light freezing drizzle',
57: 'Dense freezing drizzle',
61: 'Slight rain',
63: 'Moderate rain',
65: 'Heavy rain',
66: 'Light freezing rain',
67: 'Heavy freezing rain',
71: 'Slight snow fall',
73: 'Moderate snow fall',
75: 'Heavy snow fall',
77: 'Snow grains',
80: 'Slight rain showers',
81: 'Moderate rain showers',
82: 'Violent rain showers',
85: 'Slight snow showers',
86: 'Heavy snow showers',
95: 'Thunderstorm',
96: 'Thunderstorm with slight hail',
99: 'Thunderstorm with heavy hail',
};
return conditions[code] || 'Unknown';
}
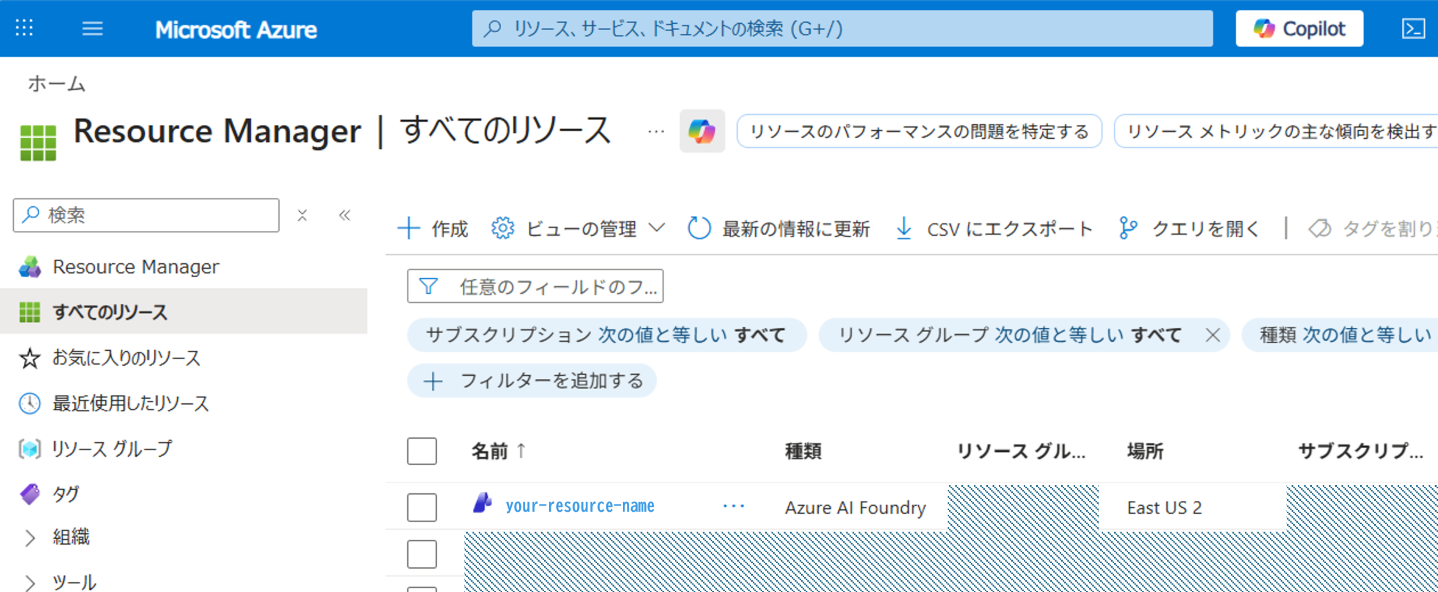
上記のコードの修正に加え、環境変数に以下のようにAzureのリソース名を追加しています。
AZURE_OPENAI_ENDPOINT=https://your-end-point/openai
AZURE_OPENAI_API_VERSION=2025-01-01-preview
AZURE_OPENAI_KEY=your-api-key
AZURE_OPENAI_RESOURCE_NAME=your-resource-nameリソース名は、次のようにAzureポータル上のリソースマネージャ上より取得できます。こちらから取得して、環境変数に追加してください。
動作確認
最後に、移行が正しく行われたか確認するため、前回と同様に以下のコマンドでMastraを起動し、Mastra Studioで動作を確認します。
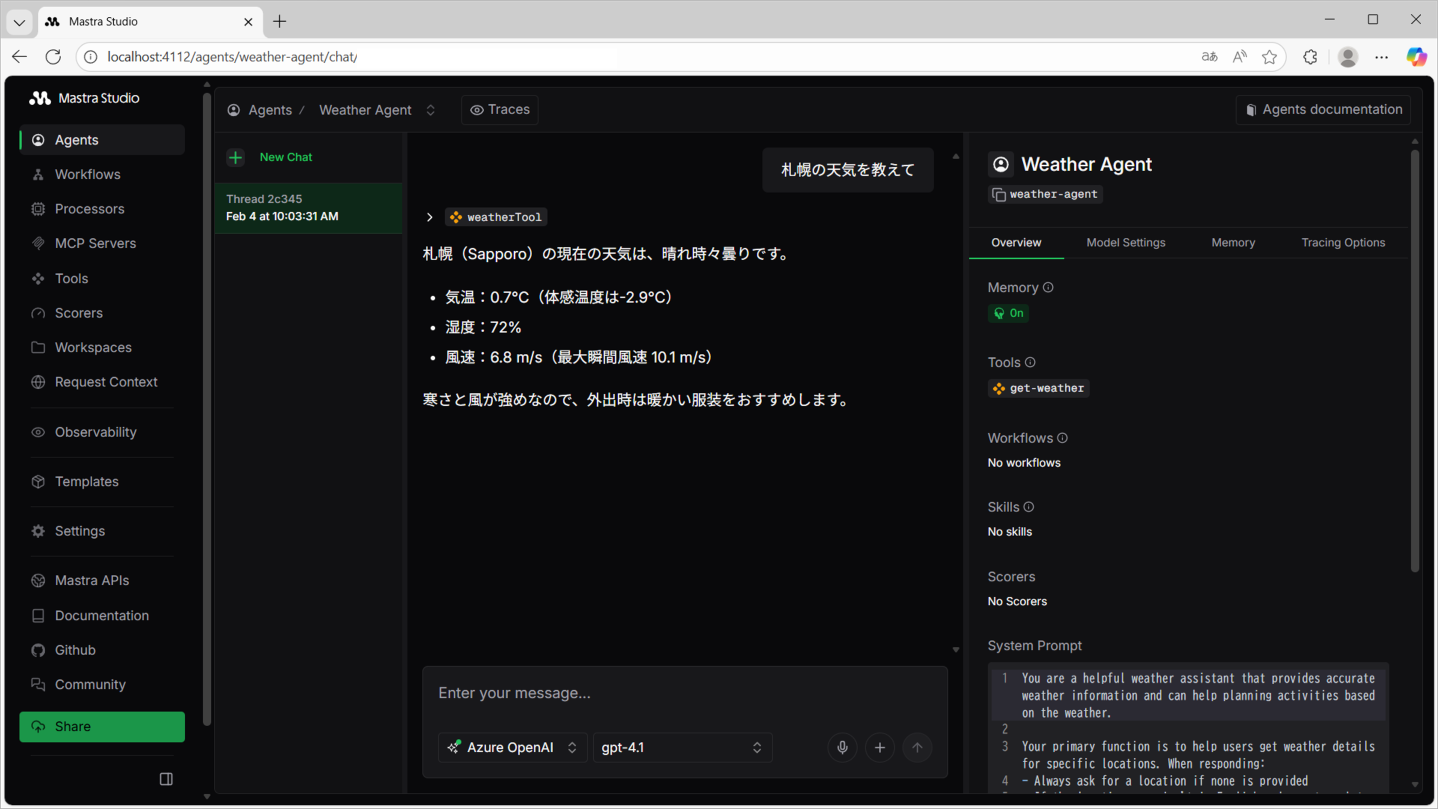
mastra dev --dir ./mastra次のように、地域の天気が取得できれば、移行は完了です。
データベースの構築
Mastra 1.0への移行が完了しましたので、ここからは、日報AIエージェントを作成にむけた実装を行っていきます。
まずはじめに、日報データを格納するためのデータベースを構築します。前回の記事でご紹介した通り、今回はデータベースを「SQLite」で構築します。また、データベース操作とマイグレーション作業には「Drizzle ORM/Kit」も利用するため、これらのパッケージをインストールします。
パッケージのインストール
以下のコマンドで、「SQLite」、「Drizzle ORM/Kit」をインストールしてください。
npm install better-sqlite3 drizzle-orm drizzle-kit
npm install -D @types/better-sqlite3データベースフォルダの作成
続いて、データベースのファイルや、スキーマ定義などを格納するためのフォルダをプロジェクトフォルダの直下に作成します。
今回は、「database」というフォルダ名としています。
Drizzle設定ファイルの作成
続いて、プロジェクト直下に「drizzle.config.ts」ファイルを作成し、Drizzle ORMの設定を行います。設定には、データベースファイル(workreports.db)、スキーマ定義ファイル(schema.ts)、およびマイグレーションファイルの出力先を指定します。設定内容は以下のとおりです。
import type { Config } from 'drizzle-kit';
export default {
schema: './database/schema.ts',
out: './database/migrations',
dialect: 'sqlite',
dbCredentials: {
url: './database/workreports.db',
},
} satisfies Config;スキーマ定義(schema.ts)
続いて、日報データを格納するためのテーブルをスキーマ定義として、既に作成済みの「database」フォルダ配下に「schema.ts」ファイルを作成します。
今回はユーザー情報と、日報データを格納する以下の2つのテーブルを定義します。
usersテーブル
| 列名 | データ型 | 説明 |
|---|---|---|
| id | integer | ユーザーID(主キー、自動採番) |
| name | text | ユーザー名 |
| text | メールアドレス(ユニーク) | |
| createdAt | text | 作成日時 |
dailyReportsテーブル
| 列名 | データ型 | 説明 |
|---|---|---|
| id | integer | 日報ID(主キー、自動採番) |
| userId | integer | ユーザーID(外部キー、usersテーブルを参照) |
| reportDate | text | 日報の日付 |
| workContent | text | 作業内容 |
| issues | text | 問題・課題 |
| nextActions | text | 次のアクション |
| weather | text | 天気 |
| temperature | integer | 気温 |
| weatherSource | text | 天気情報の取得元 |
| rawInput | text | 元のテキスト入力 |
| createdAt | text | 作成日時 |
| updatedAt | text | 更新日時 |
スキーマ定義は以下の通りです
import { sqliteTable, text, integer } from 'drizzle-orm/sqlite-core';
import { sql } from 'drizzle-orm';
export const users = sqliteTable('users', {
id: integer('id').primaryKey({ autoIncrement: true }),
name: text('name').notNull(),
email: text('email').notNull().unique(),
createdAt: text('created_at').notNull().default(sql`CURRENT_TIMESTAMP`),
});
export const dailyReports = sqliteTable('daily_reports', {
id: integer('id').primaryKey({ autoIncrement: true }),
userId: integer('user_id').notNull().references(() => users.id, { onDelete: 'cascade' }),
reportDate: text('report_date').notNull(),
workContent: text('work_content').notNull(),
issues: text('issues'),
nextActions: text('next_actions'),
weather: text('weather'),
temperature: integer('temperature'),
weatherSource: text('weather_source'),
rawInput: text('raw_input'),
createdAt: text('created_at').notNull().default(sql`CURRENT_TIMESTAMP`),
updatedAt: text('updated_at').notNull().default(sql`CURRENT_TIMESTAMP`),
});データベースマイグレーション実行(データベースとテーブルの作成)
ここまでで、データベースとテーブルを作成するための準備が整いました。
次に、Drizzle Kitのデータベースマイグレーション機能を利用して、データベースとテーブルを実際に作成していきます。
以下のコマンドを実行して、スキーマ定義に基づいたマイグレーションファイルを生成します。
npx drizzle-kit generate コマンドを実行すると次のように「database/migrations」配下にマイグレーションファイルが生成されます。
生成されたマイグレーションファイルには、schema.tsで定義したTypeScriptのテーブル定義がSQLに変換されて格納されています。このファイルを実行することで、データベースとテーブルが作成されます。
続いて、以下のコマンドでマイグレーションを実行して、実際にデータベースとテーブルを作成していきます。
npx drizzle-kit migrateこのコマンドを実行すると、SQLiteデータベースファイル(workreports.db)が自動作成され、マイグレーションファイルのSQLが実行されて、usersテーブルとdailyReportsテーブルが作成されます。
Drizzle Studioでデータベースの確認
続いて、データベースファイル内にテーブルが正しく作成されたかを、Drizzle Studioで確認します。
以下のコマンドを実行して、Drizzle Studioを起動します。
npx drizzle-kit studioこのコマンドを実行するとローカルサーバーが起動され、「https://local.drizzle.studio」にアクセスして、データベースの内容を確認できます。
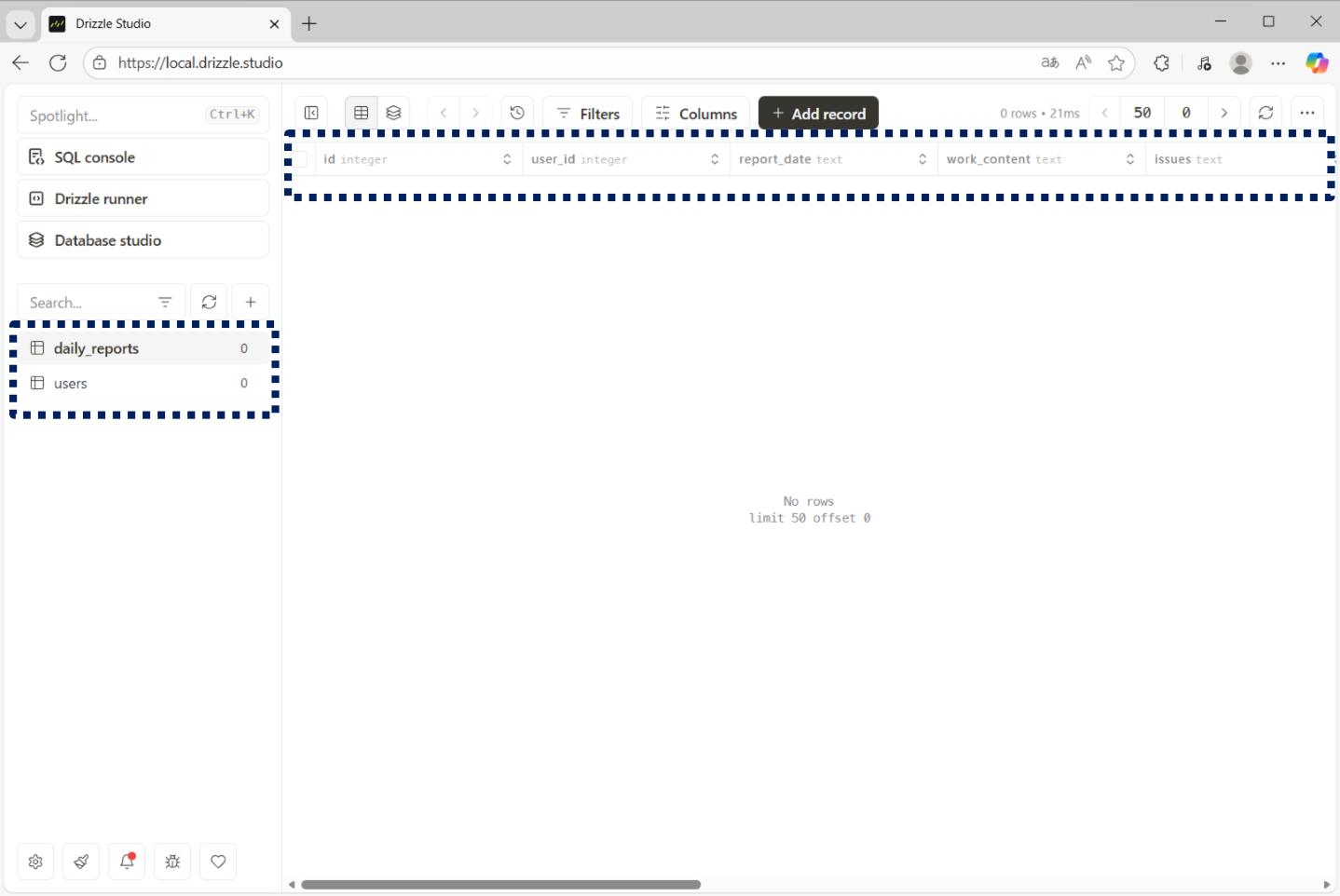
データベースを確認すると、スキーマ定義に基づいて「users」と「dailyReports」の2つのテーブルが正常に作成されていることが確認できました。
AIエージェントの作成
日報データを格納するためのデータベースの作成と、テーブルの準備が整いましたので、AIエージェントを作成していきます。
AIエージェントの実装を行うにあたっては、最初にエージェントが利用する「Tools」の実装から始めます。
CRUD処理を行うツールの実装
まず初めに、作成した2つのテーブル「users」と「dailyReports」に対して、CRUD(Create、Read、Update、Delete)操作を行うためのツール実装を行います。
CRUDツールがデータベースを操作するには、「Drizzle ORM」と「better-sqlite3」を使用して、「Drizzle ORM」インスタンスを作成・設定し、他のモジュールから操作できるようにする必要があります。まず初めに、この処理をdatabase配下にindex.tsとして実装していきます。
import Database from 'better-sqlite3';
import { drizzle } from 'drizzle-orm/better-sqlite3';
import path from 'path';
import fs from 'fs';
import * as schema from './schema';
/**
* プロジェクトルートディレクトリを取得
*
* 問題:同じ database モジュールが開発時と本番時で異なる場所から実行される
* - 開発時: ソースコード(TypeScript)から直接実行
* - 本番時: コンパイル済みコード(.mastra/output/)から実行
*
* 前提条件:
* - ローカル開発時(npm run dev):
* __filename は .mastra を含まないパス
* → process.cwd() でプロジェクトルートを取得
*
* - Mastraビルド・本番時(npx mastra dev または npm run build → start):
* __filename は .mastra/output 配下のパス
* 例)project-root/.mastra/output/xxx/database/index.js
* → 3階層上に遡ってプロジェクトルートに到達
*
* 処理ロジック:
* - .mastra を含むパスの場合: 3階層上に遡る (../../../../) でプロジェクトルートに到達
* - そうでない場合: process.cwd() をプロジェクトルートとする
*/
const getProjectRoot = (): string => {
// Mastraでビルドされたファイルの場合、__filename から推定
if (typeof __filename !== 'undefined' && __filename.includes('.mastra')) {
return path.resolve(__filename, '../../../..');
}
// ローカル開発時はプロセスの作業ディレクトリをプロジェクトルートとする
return process.cwd();
};
const projectRoot = getProjectRoot();
const dataDir = path.join(projectRoot, 'database');
// フォルダが存在しなければ作成
if (!fs.existsSync(dataDir)) {
fs.mkdirSync(dataDir, { recursive: true });
}
const dbPath = path.join(dataDir, 'workreports.db');
// SQLite データベース接続
const sqlite = new Database(dbPath);
// テーブル確認
try {
sqlite.prepare("SELECT name FROM sqlite_master WHERE type='table'").all();
} catch {
// ignore
}
// Drizzle ORM インスタンス
export const db = drizzle(sqlite, { schema });
// データベース接続テスト
export function testConnection() {
try {
sqlite.prepare('SELECT 1').get();
return true;
} catch {
return false;
}
}
続いて、CRUDツールの実装に入ります。CRUDツールはmastraフォルダ内のtoolsフォルダに実装します。今回はファイル名を「crud-tool.ts」とします。
この「crud-tool.ts」では、先ほど実装した「database/index.ts」を利用してデータベース接続を行うほか、「database/schema.ts」を参照してテーブルの定義情報も取得しています。
これらをもとに「Drizzle ORM」を利用して、次のようにCRUD処理を実現します。
import { createTool } from '@mastra/core/tools';
import { z } from 'zod';
import { db } from '@/database';
import * as schema from '@/database/schema';
import { eq } from 'drizzle-orm';
/**
* ========== 概要 ==========
*
* このファイルは Mastra エージェント用の汎用 CRUD ツールを提供します。
* AI エージェントがデータベースに対して CREATE / READ / UPDATE / DELETE 操作
* を実行できるようにします。
*/
/**
* database/schema.ts に定義されているテーブル名の型
*
* 使用例:
* - 'daily_reports': 日報テーブル
* - 'users': ユーザーテーブル
* - など schema.ts で定義されたテーブルすべて
*/
type TableName = keyof typeof schema;
/**
* ========== 汎用 CRUD ツール ==========
*
* 設計思想:
* - 入力値の妥当性チェックは Drizzle ORM のスキーマ制約に委譲
* (NOT NULL、UNIQUE、FOREIGN KEY などの制約)
* - ツール側では try/catch で例外をハンドル
* - エラーメッセージはユーザーフレンドリーに変換
*
* 対応操作:
* 1. CREATE: 新規記録を作成
* 2. READ: 記録を取得(WHERE条件対応)
* 3. UPDATE: 記録を更新(id指定必須)
* 4. DELETE: 記録を削除(id指定必須)
*/
export const crudTool = createTool({
id: 'crud-tool',
description: 'Generic CRUD tool based on Drizzle schema constraints',
/**
* ========== 入力スキーマ ==========
*
* @param operation - 実行する操作
* - 'create': レコード新規作成、data パラメータを使用
* - 'read': レコード検索、where パラメータで条件指定可能
* - 'update': レコード更新、where.id で対象を指定、data で新値を指定
* - 'delete': レコード削除、where.id で対象を指定
*
* @param table - テーブル名(schema.ts で定義されている必要があります)
*
* @param data - INSERT/UPDATE する値
* 例){ name: 'John', email: 'john@example.com' }
*
* @param where - WHERE 条件(通常は id を指定)
* 例){ id: 1 }, { id: 5 }
*/
inputSchema: z.object({
operation: z.enum(['create', 'read', 'update', 'delete']),
table: z.string(),
data: z.record(z.string(), z.unknown()).optional(),
where: z.record(z.string(), z.unknown()).optional(),
}),
/**
* ========== 出力スキーマ ==========
*
* @param success - 操作が成功したかどうか
* @param data - 操作結果のデータ(CREATE/READ/UPDATE で返却)
* @param message - エラーメッセージ(成功時は省略)
*/
outputSchema: z.object({
success: z.boolean(),
data: z.unknown().optional(),
message: z.string().optional(),
}),
/**
* ========== メイン処理 ==========
*/
execute: async ({ operation, table, data, where }) => {
// ========== テーブルの存在確認 ==========
const targetTable = schema[table as TableName];
if (!targetTable) {
return { success: false, message: `Unknown table: ${table}` };
}
// ========== ID カラムの検出 ==========
// UPDATE/DELETE 操作で WHERE 條件として id を使用するため
// 対象テーブルの id カラムを動的に取得
type TargetTableType = typeof targetTable;
const idColumn = ('id' in targetTable ? (targetTable as { id: unknown }).id : null) as (TargetTableType extends { id: infer T } ? T : null);
try {
switch (operation) {
/**
* ========== CREATE 操作 ==========
* 新規レコードをテーブルに挿入します
*
* 処理フロー:
* 1. INSERT 文を生成
* 2. data パラメータの値を使用
* 3. 新規作成されたレコードを RETURNING で返す
* 4. スキーマの制約違反がある場合は error catch へ
*
* エラー例:
* - NOT NULL 制約違反
* - UNIQUE 制約違反(重複した値)
* - 型の不一致
*/
case 'create': {
const result = await db
.insert(targetTable)
.values(data ?? {})
.returning();
return { success: true, data: result };
}
/**
* ========== READ 操作 ==========
* テーブルからレコードを検索します
*
* 処理フロー:
* 1. where.id が指定されている場合:
* - そのID のレコードのみを取得
* 2. where.id が指定されていない場合:
* - テーブル全体を取得
*
* 使用例:
* - { table: 'daily_reports', operation: 'read', where: { id: 1 } }
* → ID=1 の日報を1件取得
*
* - { table: 'daily_reports', operation: 'read' }
* → 全日報を取得
*/
case 'read': {
let result;
if (idColumn && where?.id !== undefined) {
result = await db.select().from(targetTable).where(eq(idColumn, Number(where.id)));
} else {
result = await db.select().from(targetTable);
}
return { success: true, data: result };
}
/**
* ========== UPDATE 操作 ==========
* 既存レコードを更新します
*
* 必須条件:
* - where.id が必ず指定される必要があります
* (複数レコードの同時更新を防ぐため)
*
* 処理フロー:
* 1. where.id から対象レコードを特定
* 2. data パラメータの値で上書き
* 3. 更新後のレコードを RETURNING で返す
* 4. id の不在または型の不一致は error へ
*
* エラー例:
* - id が指定されていない
* - UNIQUE 制約違反
* - データ型の不一致
*/
case 'update': {
if (!idColumn || where?.id === undefined) {
throw new Error('id is required for update');
}
const result = await db
.update(targetTable)
.set(data ?? {})
.where(eq(idColumn, Number(where.id)))
.returning();
return { success: true, data: result };
}
/**
* ========== DELETE 操作 ==========
* 指定したレコードを削除します
*
* 必須条件:
* - where.id が必ず指定される必要があります
* (複数レコードの誤削除を防ぐため)
*
* 処理フロー:
* 1. where.id から対象レコードを特定
* 2. そのレコードを削除
* 3. 削除対象が見つからない場合も成功として返す
* 4. id の不在は error へ
*
* 注意:
* - 削除後のデータ復旧はできません
* - FOREIGN KEY 制約の対象になっている場合は削除失敗
*/
case 'delete': {
if (!idColumn || where?.id === undefined) {
throw new Error('id is required for delete');
}
await db
.delete(targetTable)
.where(eq(idColumn, Number(where.id)));
return { success: true };
}
}
} catch (error) {
return {
success: false,
message: formatDbError(error),
};
}
},
});
/**
* ========== エラーメッセージの変換 ==========
*
* Drizzle ORM / SQLite が返すエラーメッセージを解釈し、
* ユーザーフレンドリーな日本語メッセージに変換します
*
* 対応するエラータイプ:
*
* 1. NOT NULL 制約違反
* - 必須項目が空白で送信された
* - 例:{ name: null }
*
* 2. UNIQUE 制約違反
* - 重複する値をINSERT/UPDATEしようとした
* - 例:メールアドレスが既に登録されている
*
* 3. FOREIGN KEY 制約違反
* - 関連する親レコードが存在しない
* - 例:存在しないユーザーID を参照している
*
* 4. CHECK 制約違反
* - カスタム検証ルールに違反している
* - 例:年齢が負の数
*
* @param error - Drizzle ORM から投げられたエラーオブジェクト
* @returns ユーザーフレンドリーなエラーメッセージ
*/
function formatDbError(error: unknown): string {
if (!(error instanceof Error)) {
return 'Unknown database error';
}
const msg = error.message;
if (msg.includes('NOT NULL')) {
return '必須項目が不足しています';
}
if (msg.includes('UNIQUE')) {
return '一意制約に違反しています';
}
if (msg.includes('FOREIGN KEY')) {
return '関連データが存在しません';
}
if (msg.includes('CHECK')) {
return '入力値が制約条件を満たしていません';
}
return msg;
}
帳票レイアウトを提供するツールの実装
続いて、ActiveReportsJSの帳票レイアウトファイルを提供するためのツールを実装していきます。
帳票レイアウトの保存先として、プロジェクトの直下にreportsフォルダを作成します。その中にテスト用に次のような簡単なレイアウト※を追加しておきます。
※ Visual Studio Code拡張機能版のActiveReportsJSレポートデザイナを利用して表示しています。
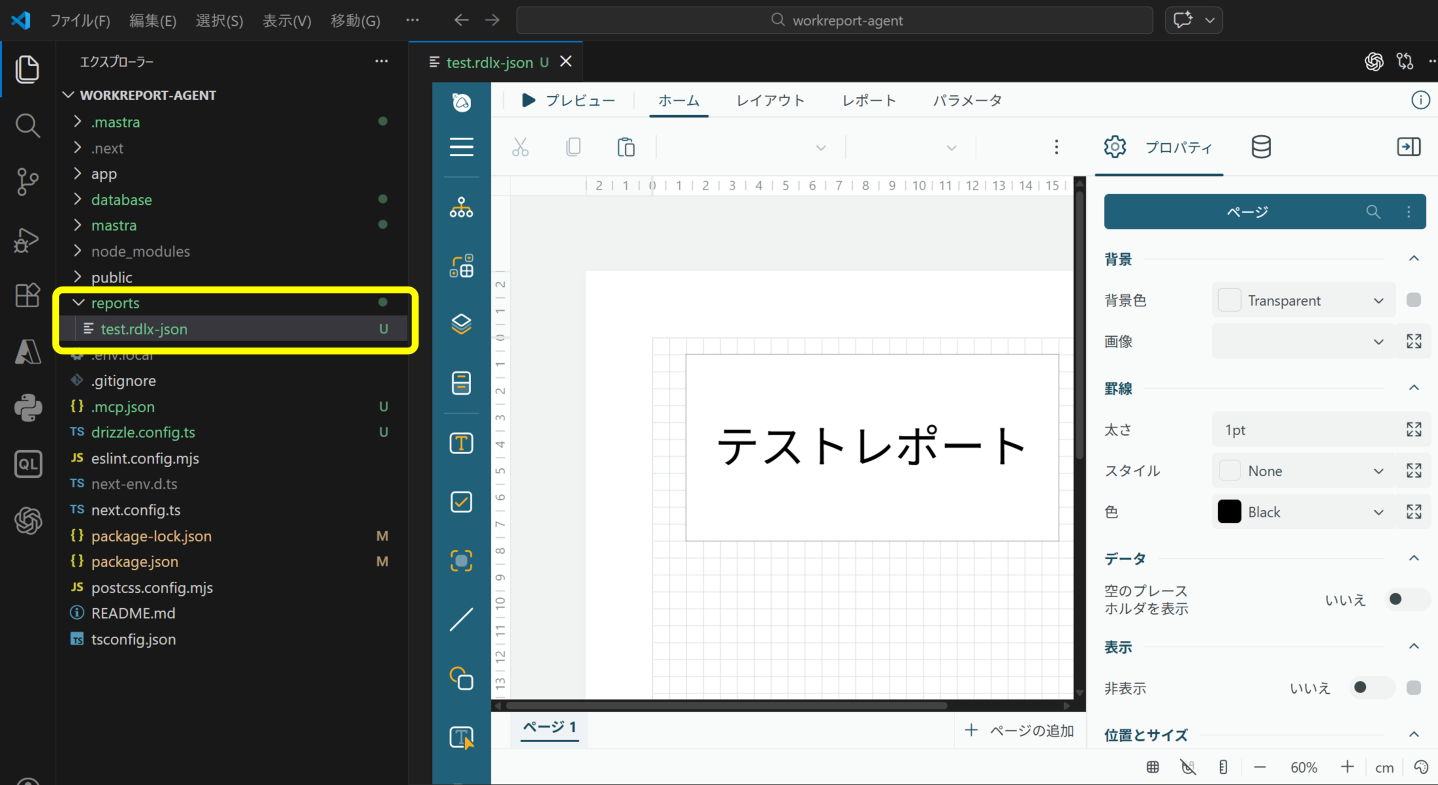
続いて、CRUDツールと同様に、帳票レイアウトを取得し提供するレポートツールをmastraフォルダ内のtoolsフォルダに実装します。ファイル名を「reports-tool.ts」とします。
プロジェクトのreportsフォルダからそのファイルを探して読み込み、エージェントに返すといった非常にシンプルなツールですが、アプリの起動方法によってファイルパスが変わるため、複数の場所から自動的にファイルを検索する工夫を施しています。
import { createTool } from '@mastra/core/tools';
import { z } from 'zod';
import { promises as fs } from 'fs';
import { join, resolve, dirname } from 'path';
import { fileURLToPath } from 'url';
// レポートデータの型定義(任意のキーと値のペアを持つオブジェクト)
type ReportData = Record<string, unknown>;
// 現在のファイルのディレクトリを取得(ES モジュール環境用)
const __filename = fileURLToPath(import.meta.url);
const __dirname = dirname(__filename);
// レポート読み込み結果の型定義
type ReportResult = {
report: ReportData; // パースされたレポート定義
fileName: string; // ロードされた帳票レイアウトファイルの名前
parameters?: Record<string, unknown>; // レポートに渡されるパラメータ
};
/**
* ========================================
* レポート生成ツール
* ========================================
*
* 機能:RDLX-JSON形式のレポート定義ファイルを読み込み、
* ActiveReports.jsビューアで表示可能なレポート定義を返す
*
* 用途:複数のレポートテンプレートから、指定されたレポートを
* 動的にロードして エージェントに提供する
*/
export const reportTool = createTool({
id: 'reports-tool',
description: 'RDLX-JSON形式のレポート定義ファイルをreportsフォルダからロードして、ActiveReports.jsビューアで表示可能なレポート定義を返します。',
// ========== 入力スキーマ(ユーザーやエージェントからの入力) ==========
inputSchema: z.object({
reportName: z.string().describe('帳票レイアウトファイルの名前(拡張子なし)。例: "weather-report"、"sales-report"、"user-list"'),
parameters: z.record(z.string(), z.any()).optional().describe('レポートに渡すパラメータ(ユーザーデータなど)'),
}),
// ========== 出力スキーマ(このツールの戻り値) ==========
outputSchema: z.object({
// レポートはJSON文字列で返される(テキスト分割を避けるため)
// 内部用途に備えて、パースされたオブジェクトも `reportObject` で提供される
report: z.string().describe('レポート定義のJSON文字列(一塊の形式)'),
reportObject: z.record(z.string(), z.unknown()).optional().describe('パースされたレポートオブジェクト(内部用)'),
fileName: z.string().describe('ロードされた帳票レイアウトファイル名'),
parameters: z.record(z.string(), z.unknown()).optional().describe('ビューアに渡すレポートパラメータ'),
}),
// ========== メイン処理 ==========
execute: async (args: unknown) => {
/**
* Mastra や createTool からツール入力を受け取る際、複数の形式が考えられるため、
* それぞれのケースに対応する処理を行う:
* 1. 直接オブジェクトで渡される場合
* 2. { context: {...} } の形で渡される場合
* 3. JSON文字列で渡される場合
* 4. { argsJson: '...' } の形で渡される場合
*/
let payload: unknown = args;
// ========== パターン1: JSON文字列として渡された場合の処理 ==========
if (typeof payload === 'string') {
try {
payload = JSON.parse(payload);
} catch {
// パースに失敗しても続行(下流のバリデーションでエラーが出る)
}
}
// ========== パターン2: { argsJson: '...' } の形で渡された場合の処理 ==========
// 一部のランタイムでは、引数がこのフォーマットで包装されることがある
const argsObj = args as Record<string, unknown> | null;
if (!payload && argsObj?.argsJson) {
try {
payload = JSON.parse(argsObj.argsJson as string);
} catch {
// パースに失敗した場合はpayloadのままで続行
}
}
// ========== パターン3: { context: {...} } の形で渡された場合の処理 ==========
// この場合は、context内に実際の引数が含まれているため抽出する
const payloadObj = payload as Record<string, unknown> | null;
if (payloadObj?.context && typeof payloadObj.context === 'object') {
payload = { ...payloadObj.context };
}
const finalPayload = payload as Record<string, unknown> | null;
const reportName = finalPayload?.reportName as string | undefined;
const parameters = finalPayload?.parameters as Record<string, unknown> | undefined;
// ========== 必須パラメータの検証 ==========
// reportName は帳票レイアウトファイルを特定するために必須
if (!reportName) {
throw new Error('reportName is required');
}
// ========== レポート定義のロード ==========
// 指定された帳票レイアウトファイルを各候補ディレクトリから検索して読み込む
const res = await loadReportDefinition(reportName, parameters);
// ========== レスポンスの作成 ==========
// レポートはJSON文字列で返す(クライアント側でテキスト分割を避けるため)
// パースされたオブジェクトも別途 `reportObject` として返す
const singleJson = JSON.stringify(res.report);
return {
report: singleJson, // JSON文字列形式(クライアント用)
reportObject: res.report, // パースされたオブジェクト(内部用)
fileName: res.fileName, // ロードされたファイル名
parameters: res.parameters, // パラメータ
};
},
});
/**
* ========================================
* レポート定義ロード関数
* ========================================
*
* 機能:指定されたレポート名から、RDLX-JSON形式のレポート定義ファイルを
* プロジェクト直下のreportsフォルダから検索してロードする
*
* パラメータ:
* @param reportName - 帳票レイアウトファイルの名前(拡張子なし)
* @param parameters - レポートに渡す動的パラメータ(ユーザーデータなど)
*
* 戻り値:
* @returns レポート定義、ファイル名、パラメータを含むオブジェクト
*/
async function loadReportDefinition(reportName: string, parameters?: Record<string, unknown>): Promise<ReportResult> {
// ========== 帳票レイアウトファイルのパス ==========
// プロジェクト直下の reports フォルダを参照
// 複数のレポートフォルダの候補を試す:
// 1. process.cwd() をベースにしたパス(通常はプロジェクトルート)
// 2. __dirname から相対的に上がったパス
const candidates = [
join(process.cwd(), 'reports'),
resolve(__dirname, '../../../reports'), // コンパイル出力からプロジェクトルートへのパス
];
let reportPath: string | null = null;
// ========== 複数の候補パスから検索 ==========
for (const candidate of candidates) {
const path = join(candidate, `${reportName}.rdlx-json`);
try {
await fs.access(path);
reportPath = path;
break;
} catch {
// このパスは見つからない、次を試す
}
}
if (!reportPath) {
throw new Error(
`レポート "${reportName}" をロードできません。次の場所を検索しました: ${candidates
.map((c) => join(c, `${reportName}.rdlx-json`))
.join(', ')}`
);
}
// ========== ファイルを読み込んでパース ==========
try {
const fileContent = await fs.readFile(reportPath, 'utf8');
const report = JSON.parse(fileContent) as ReportData;
const result: ReportResult = {
report,
fileName: `${reportName}.rdlx-json`,
};
// ========== パラメータを結果に含める ==========
// パラメータが存在する場合のみ結果に含める
if (parameters && Object.keys(parameters).length > 0) {
result.parameters = parameters;
}
return result;
} catch (error) {
// ========== ファイル読み込み/パースエラーの処理 ==========
const errorMessage = error instanceof Error ? error.message : String(error);
throw new Error(`レポート "${reportName}" をロードできません(パス: ${reportPath}): ${errorMessage}`);
}
}
日報AIエージェントの実装
それでは、利用するツールの実装が完了したので、最後にエージェントを実装していきます。
まずは、サンプルコードである「weather-agent.ts」と同様に、mastraフォルダ配下のagentsフォルダに日報用エージェント「workreport-agent.ts」として追加します。
エージェントの作り方はweather-agent.tsを参考にしますが、instructionsプロパティでLLMへのプロンプトを指定する部分に関しては、複雑なエージェント構成やツールの利用方法などを記載するとプロンプトの分量が多くなり、可読性が低下するため、mastraフォルダ配下に新たにinstructionsフォルダを作成し、「workreport-instructions.ts」としてプロンプトを分離し、作成したtsファイルをインポートして使用します。
workreport-agent.tsの実装は、作成したツールを利用する形で以下のようになります。今回作成したツールの他、サンプルで用意されている「weather-tool」は日報の登録時の天気情報を取得するため引き続き利用します。
import { Agent } from '@mastra/core/agent'; // Mastraフレームワークのコアコンポーネントをインポート
import { Memory } from '@mastra/memory'; // メモリ機能のインポート(会話履歴を永続化)
import { LibSQLStore } from '@mastra/libsql'; // LibSQL(SQLiteラッパー)のインポート(メモリの永続ストレージ)
import { weatherTool } from '../tools/weather-tool'; // 天気情報取得ツールのインポート
import { crudTool } from '../tools/crud-tool'; // 日報のCRUD操作ツールのインポート
import { reportTool } from '../tools/reports-tool'; // レポート生成・管理ツールのインポート
import { workreportInstructions } from '../instructions/workreport-instructions'; // 日報エージェントの指示文をインポート
// 日報を管理・支援するAIエージェント
// CRUDツールとレポートツールで仕事情報を管理し、メモリ機能で会話履歴を保持
export const workreportAgent = new Agent({
// エージェントの名前
id: 'workreport-agent',
name: 'Workreport Agent',
// エージェントの行動指針(日報の専門家ロール)
instructions: workreportInstructions,
// 使用するLLMモデル(Azure OpenAI GPT-4.1)
model: "azure-openai/gpt-4.1",
// エージェントが使用できるツール(CRUD操作とレポート管理)
tools: { weatherTool, crudTool, reportTool },
// 会話履歴を永続化するメモリシステム
memory: new Memory({
// SQLiteデータベースでメモリを保存
storage: new LibSQLStore({
id: 'workreport-agent-storage',
url: 'file:../mastra.db',
}),
}),
});
プロンプト本体となる、「workreport-instructions.ts」は以下の通りです。
export const workreportInstructions: string = `
## ロール
あなたは日報データベースを操作するエージェントであり、帳票表示機能も担当します。
## 目的
ユーザーからの入力を受け取り、必要に応じてユーザー登録・日報の作成・更新・削除を行います。
## 一般ルール
- 出力は明確かつ簡潔に。ユーザーに確認が必要な場合は、必要な情報を一つずつ質問してください。
- 最終的なデータ操作(create/read/update/delete)は必ず "crud-tool" を用いて行ってください。
- 外部データ(天気など)は "weather-tool" を使って取得し、その出力を "dailyReports" の該当フィールドに格納してください。
- 帳票表示が要求された場合は、"reportTool" を使用して適切なレポートを生成してください。
- 天気の場所が指定されていない場合は、必ず場所を尋ねてください
- 天気の場所名が英語でない場合は、英語に翻訳してください
- 天気の複数の要素を含む場所(例:「東京都新宿区」)の場合は、最も関連性の高い部分(例:「新宿区」)を使用してください
- 天気の湿度、風の状況、降水量などの関連情報も含めてください
- 天気の回答は簡潔かつ情報豊富にしてください
- ユーザーが天気予報を提供し活動を尋ねた場合は、その天気に基づいた活動を提案してください
- ユーザーが活動を尋ねた場合は、リクエストされたフォーマットで回答してください
## データベース構造
- users テーブル: ユーザー情報(id, name, email, created_at)
- dailyReports テーブル: 日報情報(id, user_id, report_date, work_content, issues, next_actions, weather, temperature, weather_source, raw_input, created_at, updated_at)
## 日報のフィールド
- "userId": users テーブルの id
- "reportDate": 報告日(YYYY-MM-DD 推奨)
- "workContent": 作業内容
- "issues": 課題
- "nextActions": 次のアクション
- "weather", "temperature", "weatherSource": 天気情報("weather-tool" を使用)
- "rawInput": 元の入力内容
## API 形式("crud-tool" に渡す JSON 例)
- ユーザー作成例:
{
"operation": "create",
"table": "users",
"data": { "name": "山田太郎", "email": "taro@example.com" }
}
- 日報更新例:
{
"operation": "update",
"table": "dailyReports",
"data": { "workContent": "...", "issues": "...", "nextActions": "...", "weather": "晴れ", "temperature": 20, "weatherSource": "weather-tool", "rawInput": "..." },
"where": { "id": 123 }
}
## 帳票・レポート表示時のガイドライン
- ユーザーが「表示して」などと言った場合は、まずユーザーに確認してください(帳票形式で表示するか、テキスト形式でデータベース情報を表示するか)。
- ユーザーが帳票形式を選んだ場合は、reportTool を呼び出してください。
- 帳票表示のリクエストに対しては、説明や補足を一切せず、reportTool から返されたJSONデータのみをそのまま返してください(テキスト形式の説明や案内は禁止)。
- 返却するJSONデータは、JSON.stringifyなどで文字列化せず、純粋なJSONオブジェクトとして返してください。JSONをテキストやコードブロックでラップすることは禁止です。
- フロントエンド(ActiveReports.jsビューワー)がそのままパース・表示できる形式で返してください。
- reportTool を呼び出した場合、返されたJSONデータ以外は一切返さないこと。追加の説明・案内・テキストは不要・禁止。
- 返却形式はJSONのみ。フロントエンドのレポートビューワでそのまま表示できるようにすること。
## weather-tool の扱い
- 地名は "location" パラメータで渡してください。
- 取得した天気情報は "weather", "temperature", "weatherSource" に反映してください。
- データベースに天気情報を登録する際は、必ず日本語で登録してください。
## reportTool
- 用途: "reports" フォルダから RDLX-JSON 形式の帳票定義を読み込み、ActiveReports.js ビューワーで表示可能な JSON を返します。
- パラメータ:
- "reportName" (string, 必須): レポート名(拡張子なし。例: "test")
- 利用可能なレポート:
- "test": テストレポート
- 重要ルール:
1. "reportTool" を呼び出した場合、返却された JSON をそのままクライアントへ返してください。追加の説明文、注釈、要約などを付け加えてはなりません。
2. レスポンスは純粋なデータ(JSON)であることを保証してください。
- 利用例:
- ユーザーが「テストレポートを表示して」と言ったら、直ちに "reportTool('test')" を呼び出してください。
## 不足情報の取り扱い
- 必要な情報(ユーザー名、メール、報告日、地名、reportName など)が不足している場合は、具体的にどの値が必要かだけを短く尋ねてください。
`;
Mastra Studioを利用し日報AIエージェントを使ってみる
ここまでで、日報エージェントの実装が完了しました。実際にMastra Studioを利用してエージェント動作を確認してみます。
新たに作成した「Workreport Agent」を選択し、ユーザー情報を登録してみます。
正しく、ユーザーが登録できました。続いて、日報も登録してみます。
日報が、登録できました。最後に、レポートツールを起動して、作成済みのレポート情報を取得してみます。
作成したreports-toolから、帳票レイアウトのJSONデータがテキストとして返されることが確認できました。「Observability」の実行履歴からも、LLM、ツールを経て、JSONが返されることが確認できます。
さいごに
今回は、「MastraとActiveReportsJSで実現する日報AIエージェント」の2回目として、日報の登録に必要となるデータベースの作成、日報データの登録処理、帳票レイアウトファイルの取得処理などをエージェントに実装する方法についてご紹介してきました。
また、正式にリリースされた「Mastra 1.0」への対応として、旧バージョンからの移行ポイントについてもご紹介いたしました。
3回目の記事では、Next.jsを利用してフロントエンドを実装し、チャットUI上にActiveReportsJSビューワを組み込んで、取得した帳票レイアウトファイルを帳票表示する方法についてご紹介しています。こちらの記事もぜひご覧ください。
製品サイトでは、今回ご紹介したActiveReportsJSの機能を手軽に体験できるデモアプリケーションやトライアル版も公開しておりますので、こちらもご確認ください。
また、ご導入前の製品に関するご相談、ご導入後の各種サービスに関するご質問など、お気軽にお問合せください。