Microsoft Excelでは、「画像からデータ」機能を利用して画像に含まれる表形式のデータをワークブックに挿入することが可能です。
「画像からデータ」機能は、Microsoft Excelのリボンメニューにある「データ」タブから「データの取得と変換」にある「画像から」-「ファイルからの画像」および「クリップボードからの画像」を実行します。
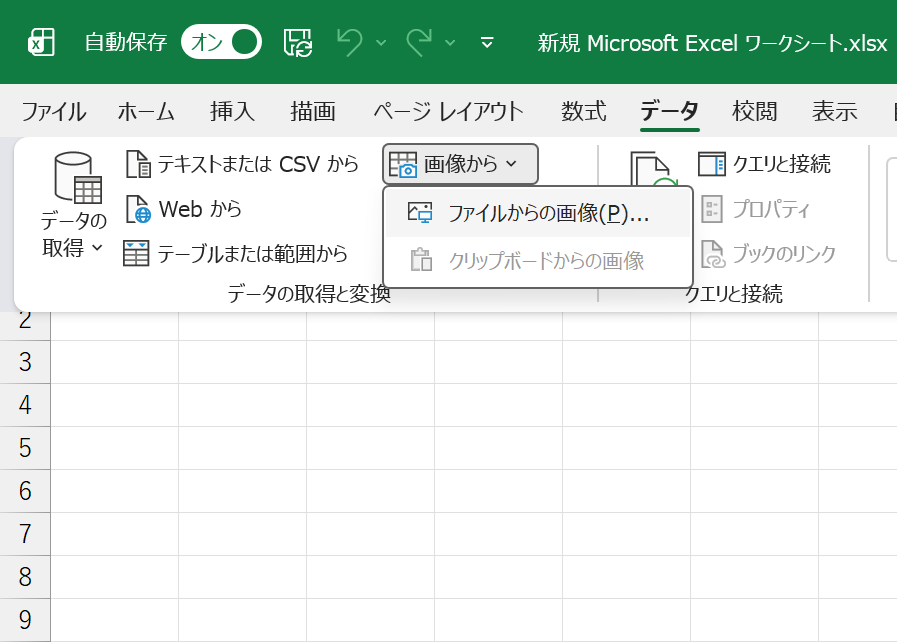
以下の画像を読み込んでみます。

画像を読み込むと右側にパネルが表示され、読み込んだ画像と認識したテキストが表形式で表示されます。ここで[データを挿入]をクリックするとそのままデータが追加されます。[確認]をクリックすると認識したテキストを修正することができます。
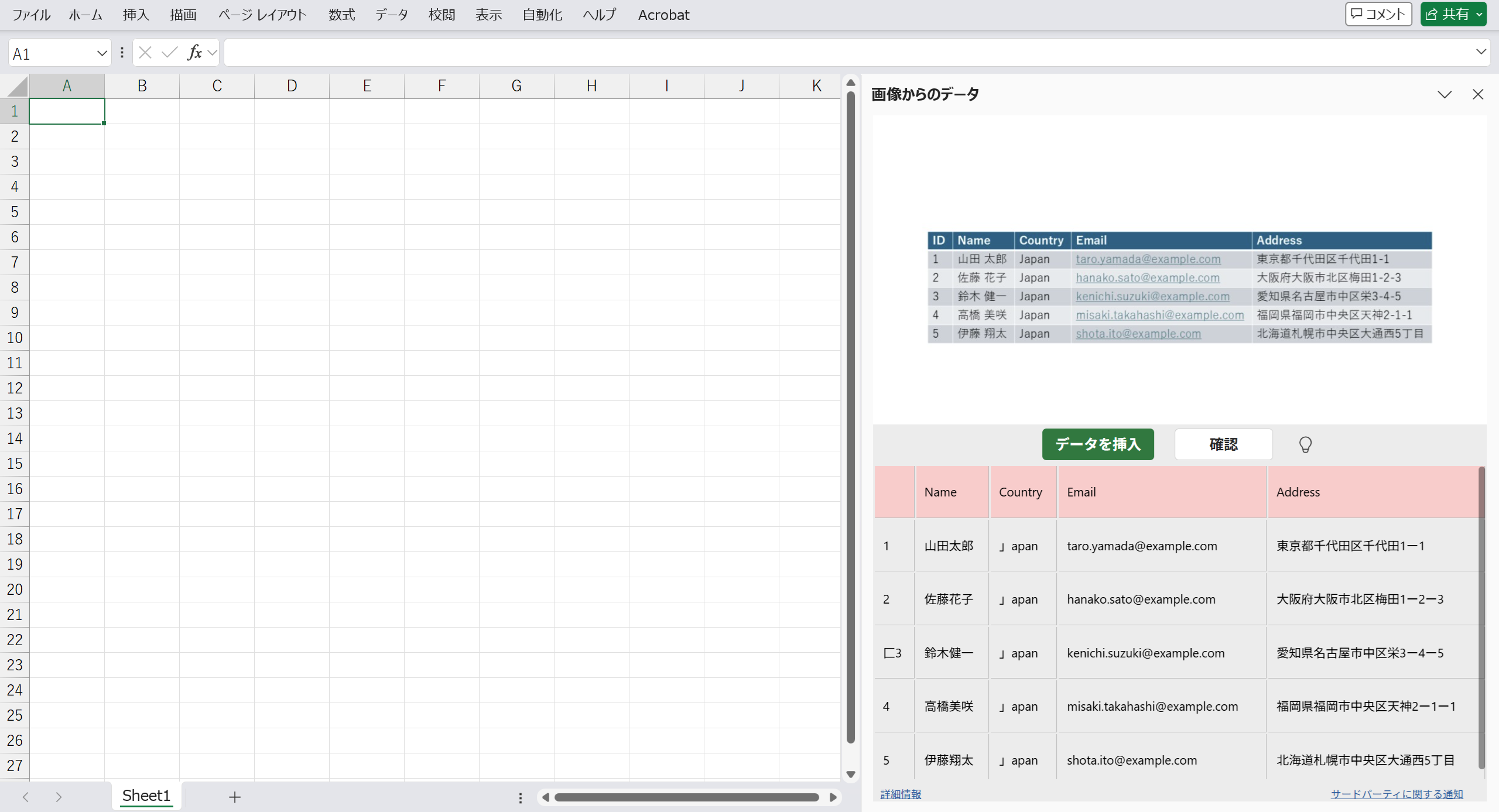
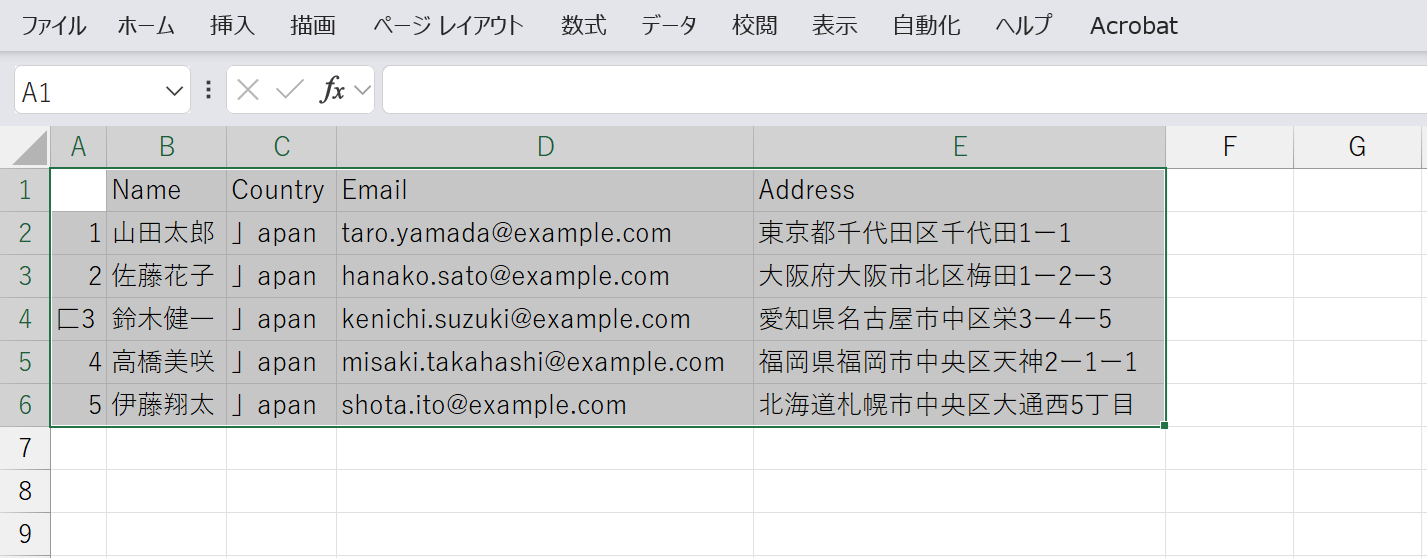
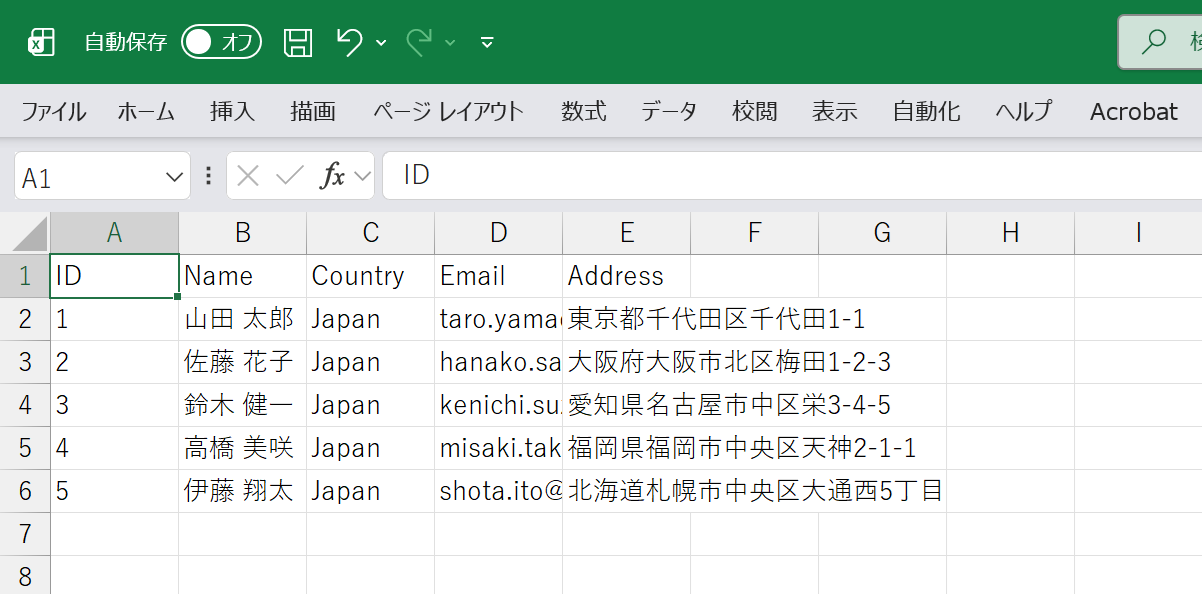
今回はそのままデータを挿入してみます。以下のように、パネルに表示された認識済みのデータがワークシートのセルに追加されます。
DioDocs for ExcelではさまざまなAIアシスタント機能が追加されていますが、Microsoft Excelのように画像から表形式のデータを挿入する機能は現時点では用意されていません。そこで本記事では、DioDocs for ExcelにAzureのサービスを組み合わせて利用して画像からデータをワークシートに追加するアプリケーションを作成する方法を紹介します。
画像からデータを抽出する機能として使用するAzureのサービスとしては、シンプルなテキスト認識(OCR)であればAzure Visionになりますが、今回はテキストデータだけではなく表形式のデータ構造も取得するので、レイアウトの解析が可能なAzure Document Intelligenceとその発展版ともいえるAzure Content Understandingを使用します。
Azure Document InteliigenceとAzure Content Understandingの違いについては、機能や用途の比較を紹介しているドキュメントが用意されているのでこちらを参考にしてください。
Azureの利用準備
前提条件
- Microsoft Foundryのリソースとプロジェクトを作成しておきます(参考)
- Document Intelligenceのリソースを作成しておきます(参考)
- Azure CLIを使用してAzureのサブスクリプションに認証を通しておきます(参考)
アプリケーションの作成(Azure Document Intelligence)
Visual Studioでコンソールアプリケーションを作成します。
NuGetパッケージマネージャーから以下のパッケージをインストールします。
- Azure.Identity
- Azure.AI.DocumentIntelligence
- DioDocs.Excel.ja
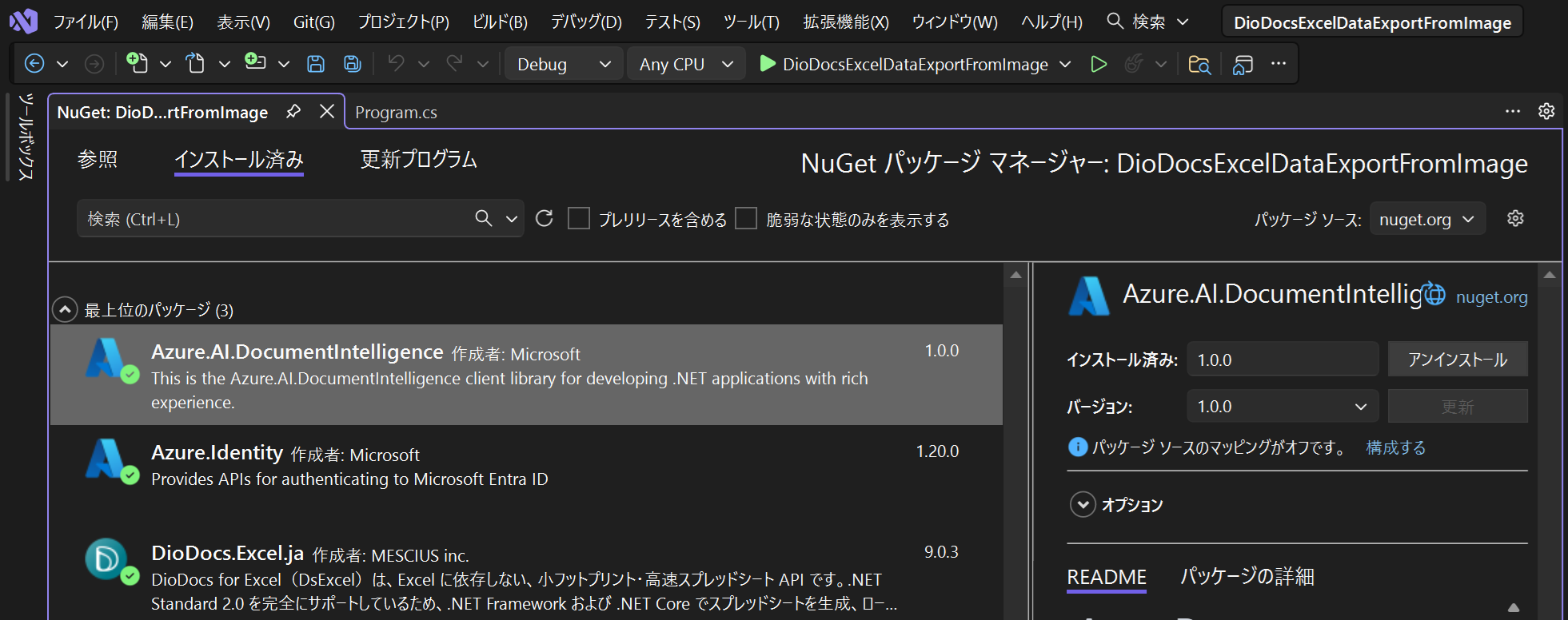
Program.csに以下のコードを追加して、Document Intelligenceのクライアントを作成します。DocumentIntelligenceClientクラスを使用してクライアントを初期化します。
using Azure;
using Azure.AI.DocumentIntelligence;
using Azure.Identity;
string endpoint = "Document Intelligenceのエンドポイント";
DefaultAzureCredential credential = new();
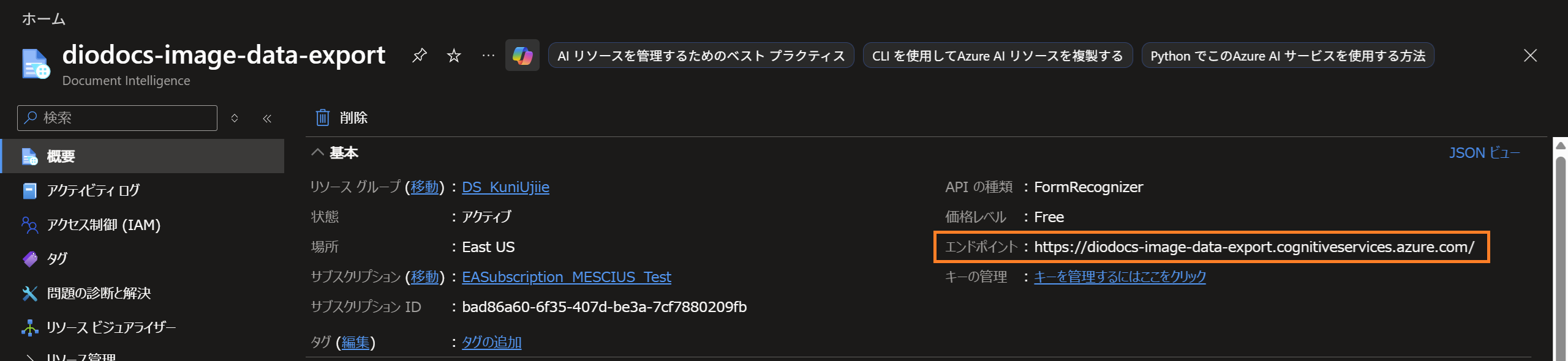
DocumentIntelligenceClient client = new(new Uri(endpoint), credential);上記の「Document Intelligenceのエンドポイント」は、作成したDocument Intelligenceの概要ページで確認できます。
対象の画像(sample-data.png)を、BinaryDataとしてAnalyzeDocumentAsyncメソッドの引数に設定します。Document Intelligenceでは事前定義済みのモデルを使用して画像を分析することができます。ここではprebuilt-layoutというレイアウト分析に特化したモデルを使用します。このモデルは表(テーブル)構造とデータを抽出することが可能です。その他のモデルについてはこちらで確認できます。
AnalyzeDocumentAsyncメソッドを実行して分析した結果は、AnalyzeResultで受け取ります。
string imagePath = "sample-data.png";
byte[] imageBytes = File.ReadAllBytes(imagePath);
var datasource = BinaryData.FromBytes(imageBytes);
Operation<AnalyzeResult> operation = await client.AnalyzeDocumentAsync(
WaitUntil.Completed,
"prebuilt-layout",
datasource);
AnalyzeResult result = operation.Value;AnalyzeResultに含まれる表データを取得します。DocumentTableで受け取った表データからさらにDocumentTableCellで各セルの行と列のインデックス(RowIndex、ColumnIndex)とデータ(Content)を受け取ることができます。そして、受け取った行と列のインデックスを基に、ワークシートのセル範囲にデータを追加する処理をDioDocs for Excelで実装します。
for (int i = 0; i < result.Tables.Count; i++)
{
DocumentTable table = result.Tables[i];
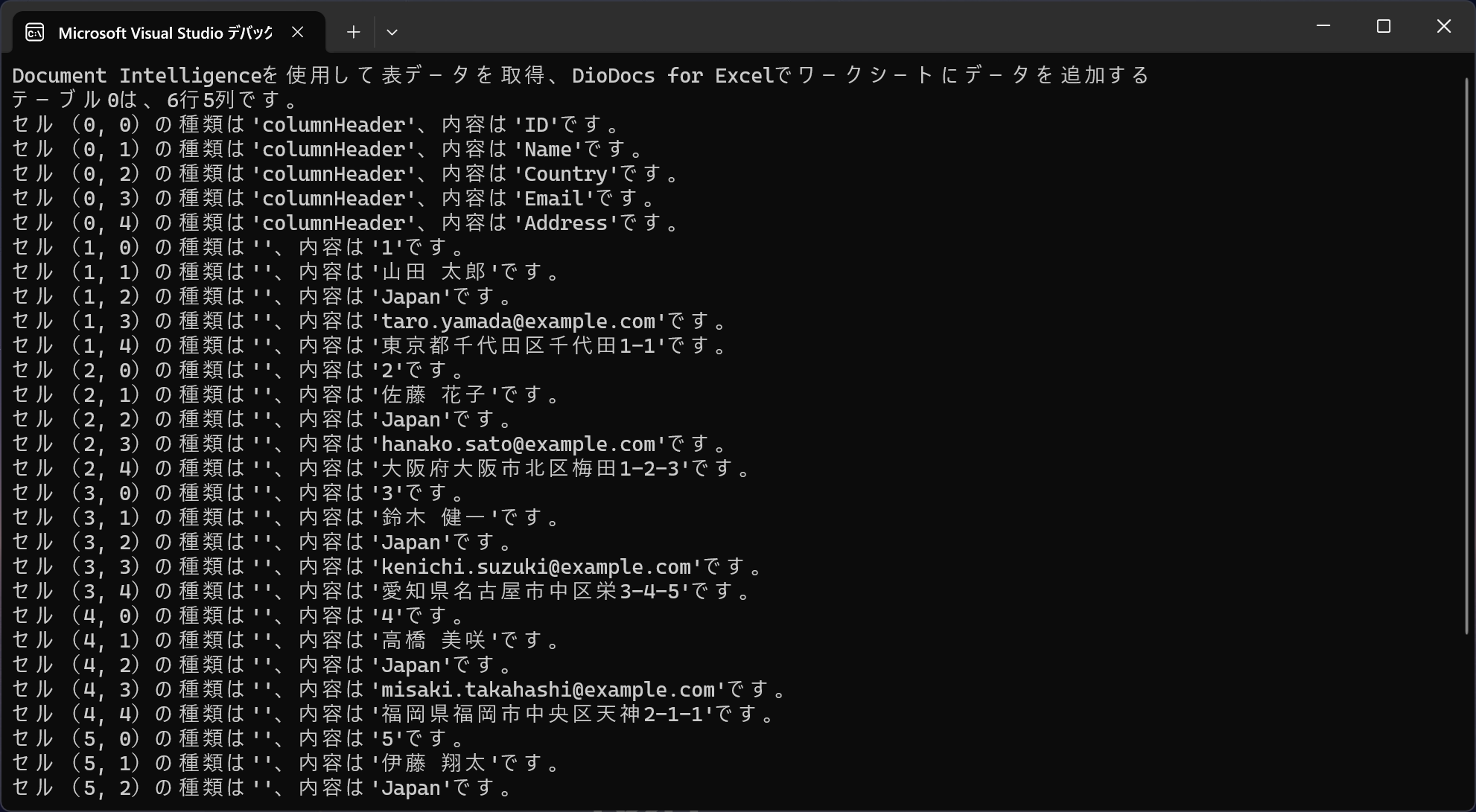
Console.WriteLine($"テーブル{i}は、{table.RowCount}行{table.ColumnCount}列です。");
Workbook workbook = new();
foreach (DocumentTableCell cell in table.Cells)
{
Console.WriteLine($"セル({cell.RowIndex}, {cell.ColumnIndex})の種類は'{cell.Kind}'、内容は'{cell.Content}'です。");
workbook.Worksheets[0].Range[cell.RowIndex, cell.ColumnIndex].Value = cell.Content;
}
workbook.Save("DataImportFromImage.xlsx");
}Visual Studioからデバッグ実行するとコンソールでは以下のように表示され、さらにExcelファイルのワークシートにデータが追加されていることが確認できます。
アプリケーションの作成(Azure Content Understanding)
基本的な処理の流れはAzure Document Intelligenceを使用する場合と同じです。変更点としては、NuGetパッケージマネージャーでAzure.AI.DocumentIntelligenceの代わりにAzure.AI.ContentUnderstandingをインストールします。
Program.csに以下のコードを追加して、Content Understandingのクライアントを作成します。DocumentIntelligenceClientクラスを使用してクライアントを初期化します。
string endpoint = "Content Understandingのエンドポイント";
DefaultAzureCredential credential = new();
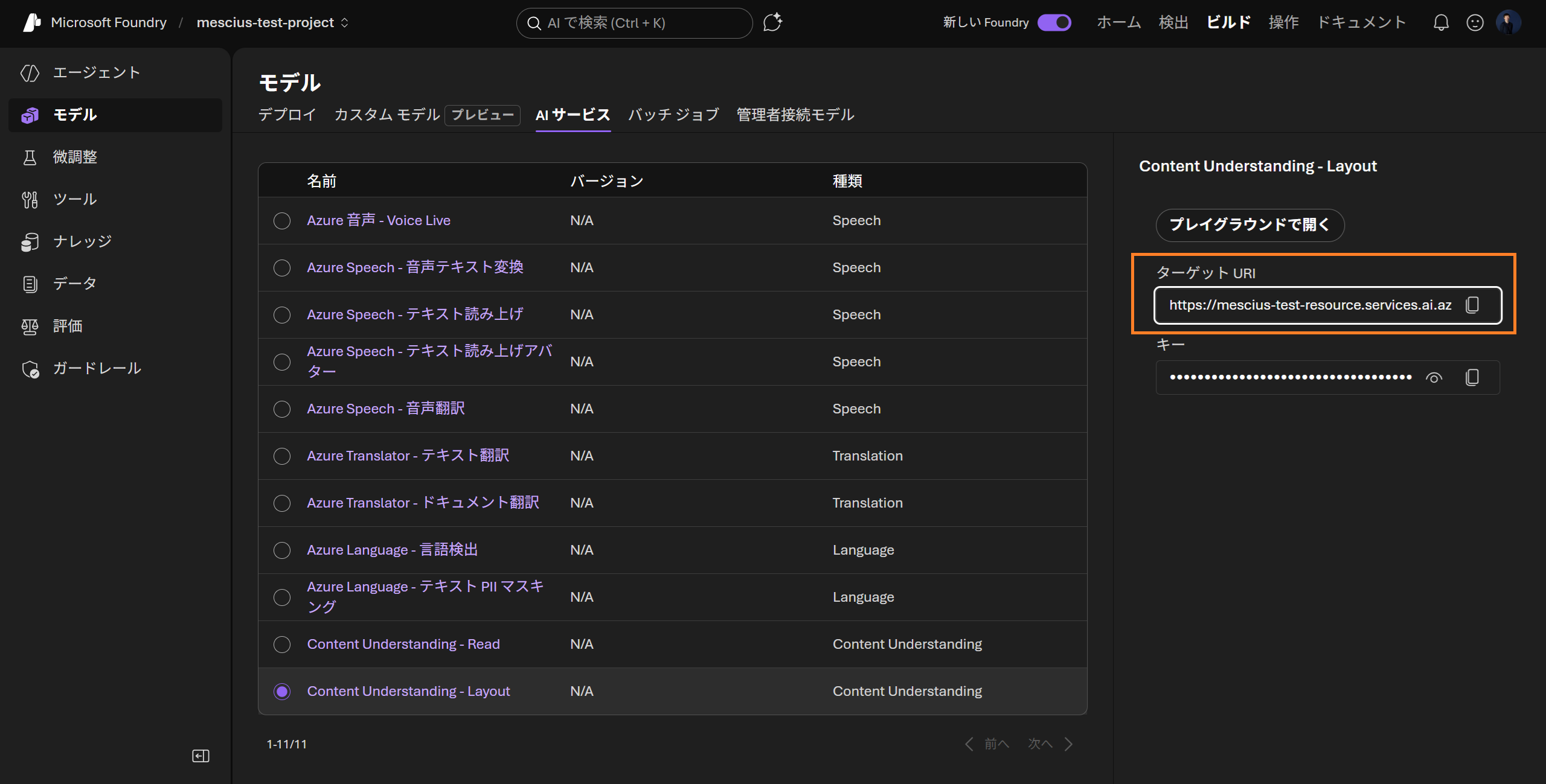
ContentUnderstandingClient client = new(new Uri(endpoint), credential);上記の「Content Understandingのエンドポイント」は、作成したMicrosoft Foundryのページで確認できます。
対象の画像(sample-data.png)を、BinaryDataとしてAnalyzeBinaryAsyncメソッドの引数に設定します。Content Understandingでも事前定義済みのモデルを使用して画像を分析することができます。Document Intelligenceと同じくprebuilt-layoutを使用します。AnalyzeBinaryAsyncAnalysisResultで受け取ります。
string filePath = "sample-data.png";
byte[] fileBytes = File.ReadAllBytes(filePath);
BinaryData binaryData = BinaryData.FromBytes(fileBytes);
Operation<AnalysisResult> operation = await client.AnalyzeBinaryAsync(
WaitUntil.Completed,
"prebuilt-layout",
binaryData);
AnalysisResult result = operation.Value;AnalysisContentに含まれる表データを取得します。DocumentTableで受け取った表データからさらにDocumentTableCellで各セルの行と列のインデックス(RowIndex、ColumnIndex)とデータ(Content)を受け取ることができます。そして、受け取った行と列のインデックスを基に、ワークシートのセル範囲にデータを追加する処理をDioDocs for Excelで実装します。
AnalysisContent content = result.Contents!.First();
if (content is DocumentContent documentContent)
{
if (documentContent.Tables != null && documentContent.Tables.Count > 0)
{
for (int i = 0; i < documentContent.Tables.Count; i++)
{
DocumentTable table = documentContent.Tables[i];
Console.WriteLine($"テーブル{i}は、{table.RowCount}行{table.ColumnCount}列です。");
Workbook workbook = new();
foreach (DocumentTableCell cell in table.Cells)
{
Console.WriteLine($"セル({cell.RowIndex}, {cell.ColumnIndex})の種類は'{cell.Kind}'、内容は'{cell.Content}'です。");
workbook.Worksheets[0].Range[cell.RowIndex, cell.ColumnIndex].Value = cell.Content;
}
workbook.Save("DataImportFromImage.xlsx");
}
}
}
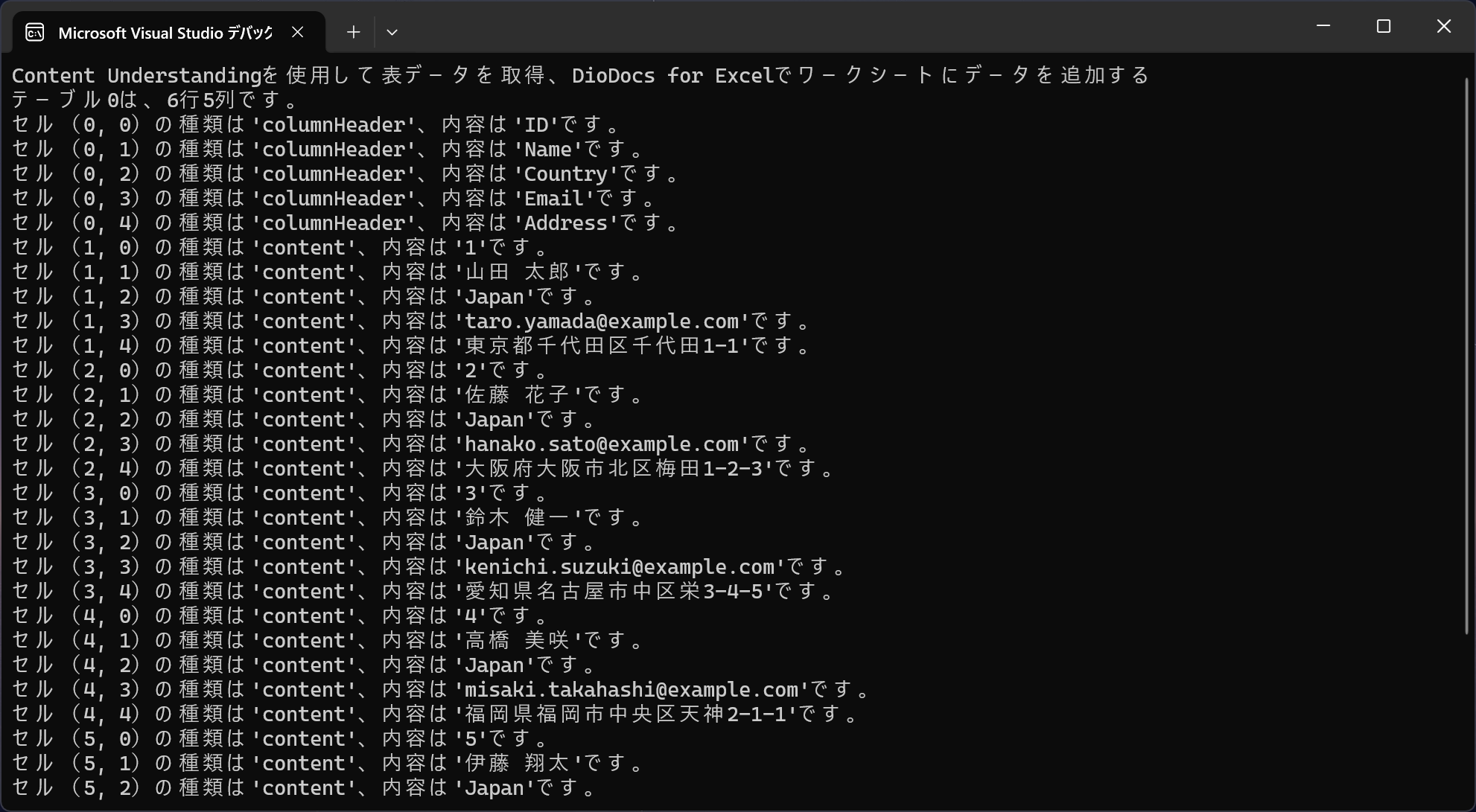
Visual Studioからデバッグ実行するとDocument Intelligenceと同じようなコンソールでの表示と、さらにExcelファイルのワークシートにデータが追加されていることが確認できます。
上記で紹介した動作を確認できるサンプルはこちらです。
さいごに
弊社Webサイトでは、製品の機能を気軽に試せるデモアプリケーションやトライアル版も公開していますので、こちらもご確認いただければと思います。
また、ご導入前の製品に関するご相談やご導入後の各種サービスに関するご質問など、お気軽にお問合せください。